
Research
Neuromorphics
- Neuromorphic Perception In this research direction, I seek to complement traditional event-based sensors, that transduce physical signals (i.e. light, sound, touch, …) into events, with a novel integrative stage that finds correlations between multiple sensory event streams in a manner akin to the cortical processing. For this, I present a new perspective to similarity detection in analog VLSI based on the well-known van Rossum distance. I am convinced this direction will offer an energy efficient approach to ‘imaging’ and enforcing neural synchrony between neuromorphic and neuronal systems with direct implications for low-power AI hardware and advanced neurorehabilitation.
Akwaboah A., Leugering J., Phillips L., Cauwenberghs G., Etienne-Cummings R. 2024. Sensing Temporal Codes and Probing System Responses with Spikes: An Active Pixel Approach. (ISCAS 2025)
EFRI BRAID: Using Proto-Object Based Saliency Inspired by Cortical Local Circuits to Limit the Hypothesis Space for Deep Learning Models
Deep learning has achieved impressive performance in many tasks, which is driven by the capacity for backpropagation to “assign credit” to a vast array of parameters. Typical networks have immensely complex computational graphs, with many options to assign credit for every computation. A large number of options comes with the benefits of being very flexible in learning, but also with costs of large energy consumption and many needed examples for learning. A selection of important (salient) features will cause inductive biases in learning, but such biases, when appropriately conditioned, can be optimally selected, as is done in biology via evolution or development. For our project, the selection mechanism will be inspired by biology or learned, and will be instantiated in software and hardware. The process of selection is akin to the attention mechanisms of mammals. We previously developed state-of-the art models, based on neurophysiology, of bottom-up and top-down attention and suggested how perceptual organization can reshape and focus attention. We showed how such mechanisms of attention which can predict human behaviors can be implemented using local circuits in the cortex and in neuromorphic hardware. We propose to construct a hybrid architecture, where local circuits implement a bottom-up attention, or saliency module that provides a “gate” for selecting features for a global learning network with a convolutional architecture. The saliency module will decrease the number of features considered for inference and for learning by including a learned prior of what features are important. We hypothesize that after determining and implementing optimal attentional mechanisms for a set of tasks/input statistics, they will substantially reduce power requirement for both inference and learning, as well as allowing learning with considerably fewer examples than traditional methods. Such a model can also help answer the question of why some visual cortex neurons have their properties explained by convolutional neural networks while others mimic saliency models, and why biology learns with few examples. We can also answer determine optimal learning architecture for hardware and benchmark them against existing systems.

Akwaboah A., , Sampson A., Goldhaber-Gordon S., Mihalas S., Niebur E., Andreou A., Etienne-Cummings R. AstroNet: Self-Modulation of Deep Feature Space Via Bottom-Up Saliency Descriptors (Submitted: 2026 Neuro-Inspired Computing Elements (NICE) Conference)
Distributed Sparse Neural Network Inference in Chip Multiprocessor Hardware
This direction focuses on efficient strategies for translating sparse neural network models into distributed processing hardware paradigms, i.e. chip multiprocessor systems e.g. SpiNNaker2*
Algorithmic and Hardware Co-Design of Event-based Local Synaptic Plasticity
The human brain expends a mere 20 watts[1] in learning and inference, exponentially lower than state-of-the-art large language models (GPT-3 and LaMDA). There is the need to innovate sustainable AI hardware as the 3.4x compute doubling per month has drastically outpaced the Moore’s law, i.e., a 2-year transistor doubling[2]. Efforts here are geared towards realizing biologically plausible learning rules such as the Hebb’s rule based Spike-Timing-Dependent Plasticity (STDP) algorithmically and corresponding in low-power neuromorphic circuits and systems implemented in mixed analog-digital VLSI. Analog subthreshold current-mode computation offers convenient realization of addition and multiplication arithmetic. Moreso, current-mode memory elements such as dynamic current mirrors can be leveraged to arrive at low-power learning engines. This has been demonstrated in our recent work presented at NEWCAS. On the Algorithmic front, we have developed LODeNNS, a linearly optimized Dendrocentric Nearest Neighbor STDP suitable for existing large-scale digital neuromorphic platforms such as the Intel Loihi and can be deployed in spatiotemporal signal applications such as object tracking and audio recognition. Future work on this include validation and application on event-based data. On the hardware front, insights from the algorithmic level are being translated in mixed signal VLSI with implications for learning at the edge and on-the-fly, i.e. low-power intelligent sensors.
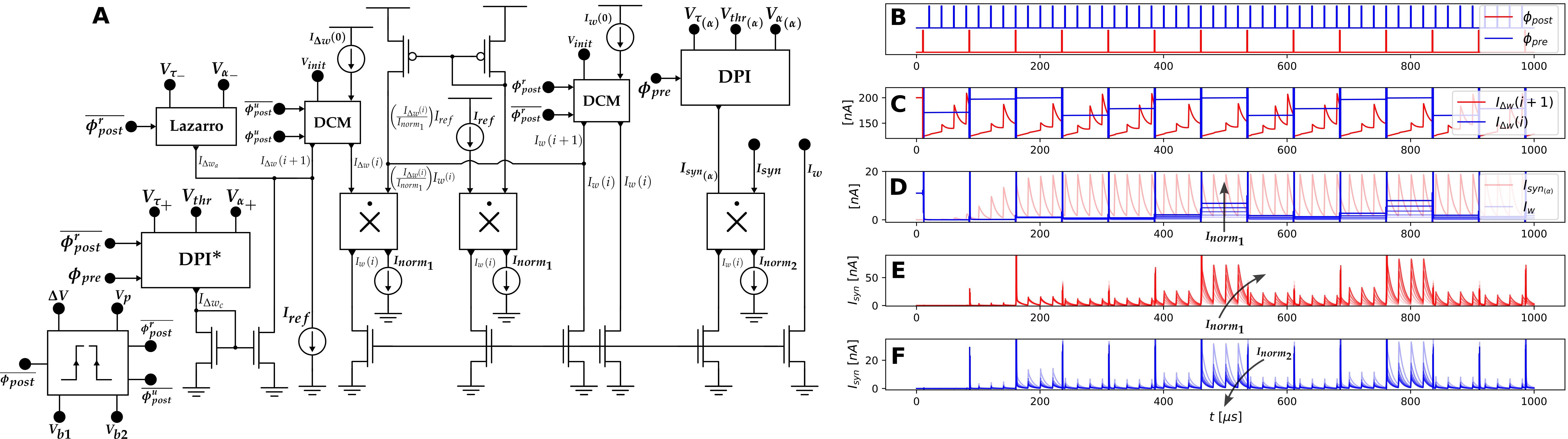
Akwaboah, A. and Etienne-Cummings, R., 2023, June. A Current-Mode Implementation of A Nearest Neighbor STDP Synapse. In 2023 21st IEEE Interregional NEWCAS Conference (NEWCAS) (pp. 1-5). IEEE.
- Neuromorphic Perception In this research direction, I seek to complement traditional event-based sensors, that transduce physical signals (i.e. light, sound, touch, …) into events, with a novel integrative stage that finds correlations between multiple sensory event streams in a manner akin to the cortical processing. For this, I present a new perspective to similarity detection in analog VLSI based on the well-known van Rossum distance. I am convinced this direction will offer an energy efficient approach to ‘imaging’ and enforcing neural synchrony between neuromorphic and neuronal systems with direct implications for low-power AI hardware and advanced neurorehabilitation.
Neural Interfaces
HermEIS: A Parallel Multichannel Electrochemical Impedance Spectrometer for Rapid Neural Electrode Characterization
The promise of increasing channel counts in high density ($> 10^4$) neural Microelectrode Arrays (MEAs) for high resolution recording comes with the curse of developing faster characterization strategies for concurrent acquisition of multichannel electrode integrities over a wide frequency spectrum. To circumvent the latency associated with the current multiplexed technique for impedance acquisition, it is common practice to resort to the single frequency impedance measurement (i.e. $Z_{1 \text{kHz}}$). This, however, does not offer sufficient spectral impedance information crucial for determining the capacity of electrodes at withstanding slow and fast-changing stimuli and recordings. In this work, we present HermEIS, a novel approach that leverages single cycle in-phase and quadrature signal integrations for reducing the massive data throughput characteristic of such high density acquisition systems. As an initial proof-of-concept, we demonstrate over $6$ decades of impedance bandwidth ($5\times10^{-2} - 5\times10^{4}\text{ Hz}$) in a parallel $4$-channel potentiostatic setup composed of a custom PCB with off-the-shelf electronics working in tandem with an FPGA.
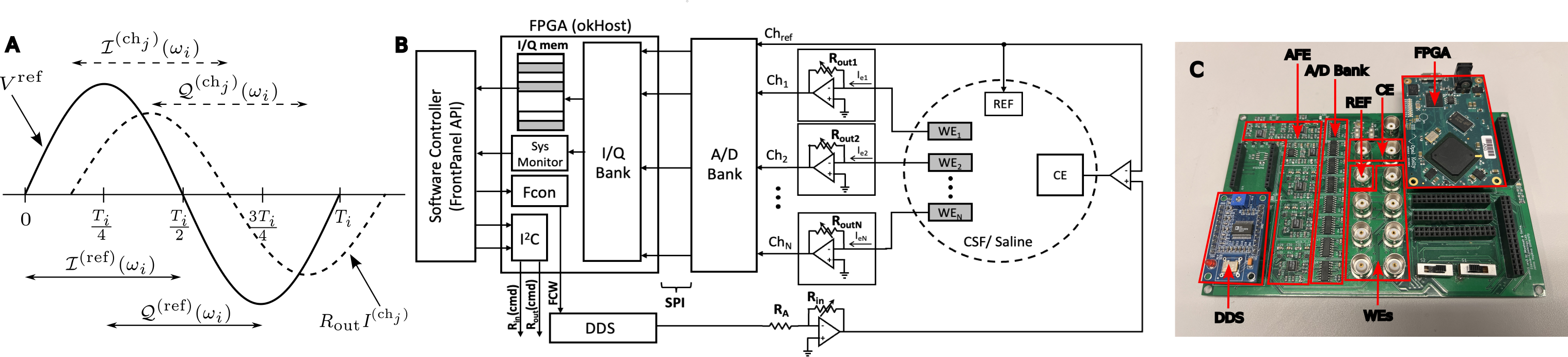
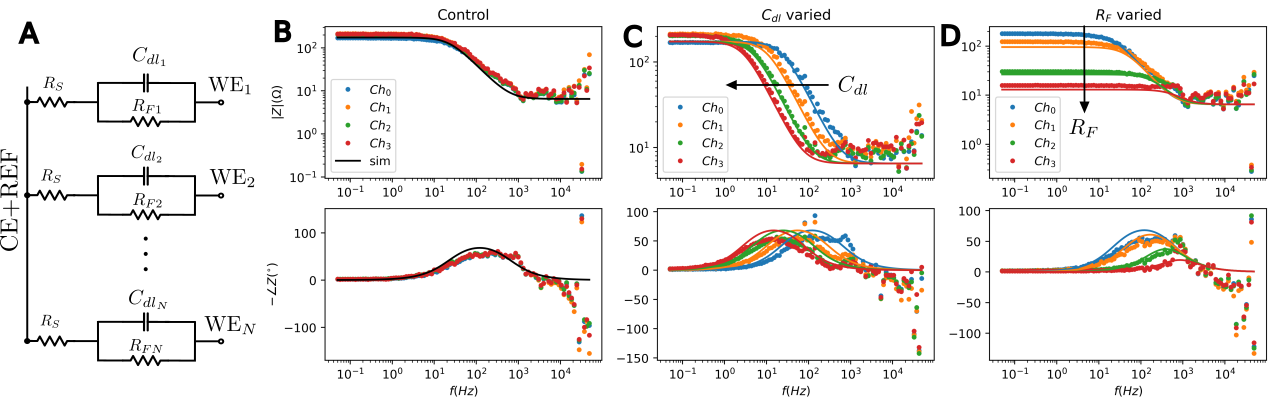
Akwaboah, A. and Etienne-Cummings, R., 2024. HermEIS: A Parallel Multichannel Approach to Rapid Spectral Characterization of Neural MEAs. arXiv preprint arXiv:2403.07758.